Review: Google Cloud Vertex AI irons out ML platform wrinkles
Vertex AI greatly improves the integration of Google Cloud’s AI/ML platform and AutoML services, combining a new unified API with very good modeling capabilities.






Contributor, InfoWorld |

-
Google Cloud Vertex AI
When I reviewed the Google Cloud AI and Machine Learning Platform last November, I noted a few gaps despite Google having one of the largest machine learning stacks in the industry, and mentioned that too many of the services offered were still in beta test. I went on to say that nobody ever gets fired for choosing Google AI.
This May, Google shook up its AI/ML platform by introducing Vertex AI, which it says unifies and streamlines its AI and ML offerings. Specifically, Vertex AI is supposed to simplify the process of building and deploying machine learning models at scale and require fewer lines of code to train a model than other systems. The addition of Vertex AI doesn’t change the Google Cloud AI building blocks, such as the Vision API and the Cloud Natural Language API, or the AI Infrastructure offerings, such as Cloud GPUs and TPUs.
Google’s summary is that Vertex AI brings Google Cloud AutoML and Google Cloud AI and Machine Learning Platform together into a unified API, client library, and user interface. AutoML allows you to train models on image, tabular, text, and video datasets without writing code, while training in AI and Machine Learning Platform lets you run custom training code. With Vertex AI, both AutoML training and custom training are available options. Whichever option you choose for training, you can save models, deploy models, and request predictions with Vertex AI.
This integration of AutoML and custom training is a huge improvement over the old Google Cloud AI/ML platform. Because each service in the old platform was developed independently, there were cases where tagged data in one service couldn’t be reused by another service. That’s all fixed in Vertex AI.
The Google AI team spent two years reengineering its machine learning stack from the Google Cloud AI and Machine Learning Platform to Vertex AI. Now that the plumbing is done and the various services have been rebuilt using the new system, the Google AI team can work on improving and extending the services.
In this review I’ll explore Vertex AI with an eye towards understanding how it helps data scientists, how it improves Google’s AI capabilities, and how it compares with AWS’ and Azure’s AI and ML offerings.
Google Cloud Vertex AI workflow
According to Google, you can use Vertex AI to manage the following stages in the machine learning workflow:
- Create a dataset and upload data.
- Train an ML model on your data:
- Train the model.
- Evaluate model accuracy.
- Tune hyperparameters (custom training only).
- Upload and store your model in Vertex AI.
- Deploy your trained model to an endpoint for serving predictions.
- Send prediction requests to your endpoint.
- Specify a prediction traffic split in your endpoint.
- Manage your models and endpoints.
That sounds very much like an end-to-end solution. Let’s look closer at the pieces that support each stage.
By the way, lots of these pieces are marked “preview.” That means they are covered by the Google Cloud Pre-GA Offerings Terms, which are similar to the terms for public beta-phase products, including the lack of SLA and the lack of guarantees about forward compatibility.
Data science notebooks
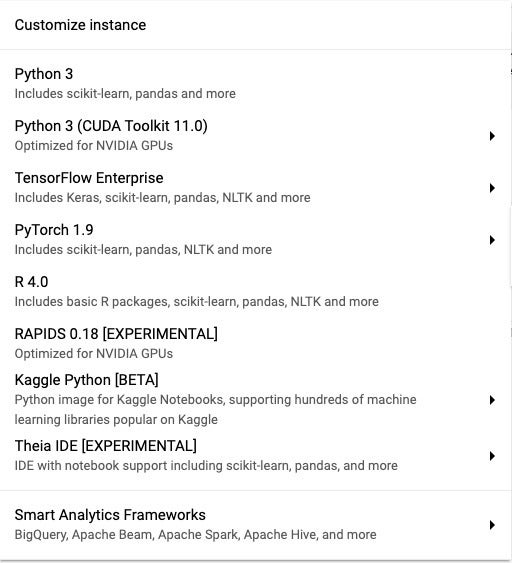
Vertex AI still supports notebooks, with an expanded set of environment types, as shown in the image below. New notebooks include JupyterLab 3.0 by default, and Python 2.x is no longer supported.
 IDG
IDG
Vertex AI JupyterLab notebook types include support for Python 3, TensorFlow Enterprise, PyTorch, R, RAPIDS, and other languages and frameworks.
Data prep and management
Data preparation and management don’t seem to have changed much, except for the addition of some Vertex AI APIs. I was hoping to see lower suggested numbers of exemplars for the image AutoML datasets, but Google still recommends 1,000 images for training. That suggests to me that the Azure Custom Vision service, which needs far fewer training images for good results, is still ahead of the Google AutoML Vision service. I imagine that Google will be improving its offerings in this area now that Vertex AI has been released.
Also, custom data labeling jobs (by humans) are still limited, because of COVID-19. You can request data labeling tasks, but only through email.
Training AutoML and other models
Google has an unusual definition of AutoML. For images, text, and video, what it calls AutoML is what most data scientists call transfer learning. For tabular data, its AutoML adheres to the standard definition, which includes automatic data prep, model selection, and training.
The trained model can be AutoML, AutoML Edge (to export for on-device use), or custom training. AutoML Edge models are smaller and often less accurate than AutoML models. Custom models can be custom Python source code (using PyTorch, Scikit-learn, TensorFlow, or XGBoost) that runs in a pre-built container, or custom Docker container images.
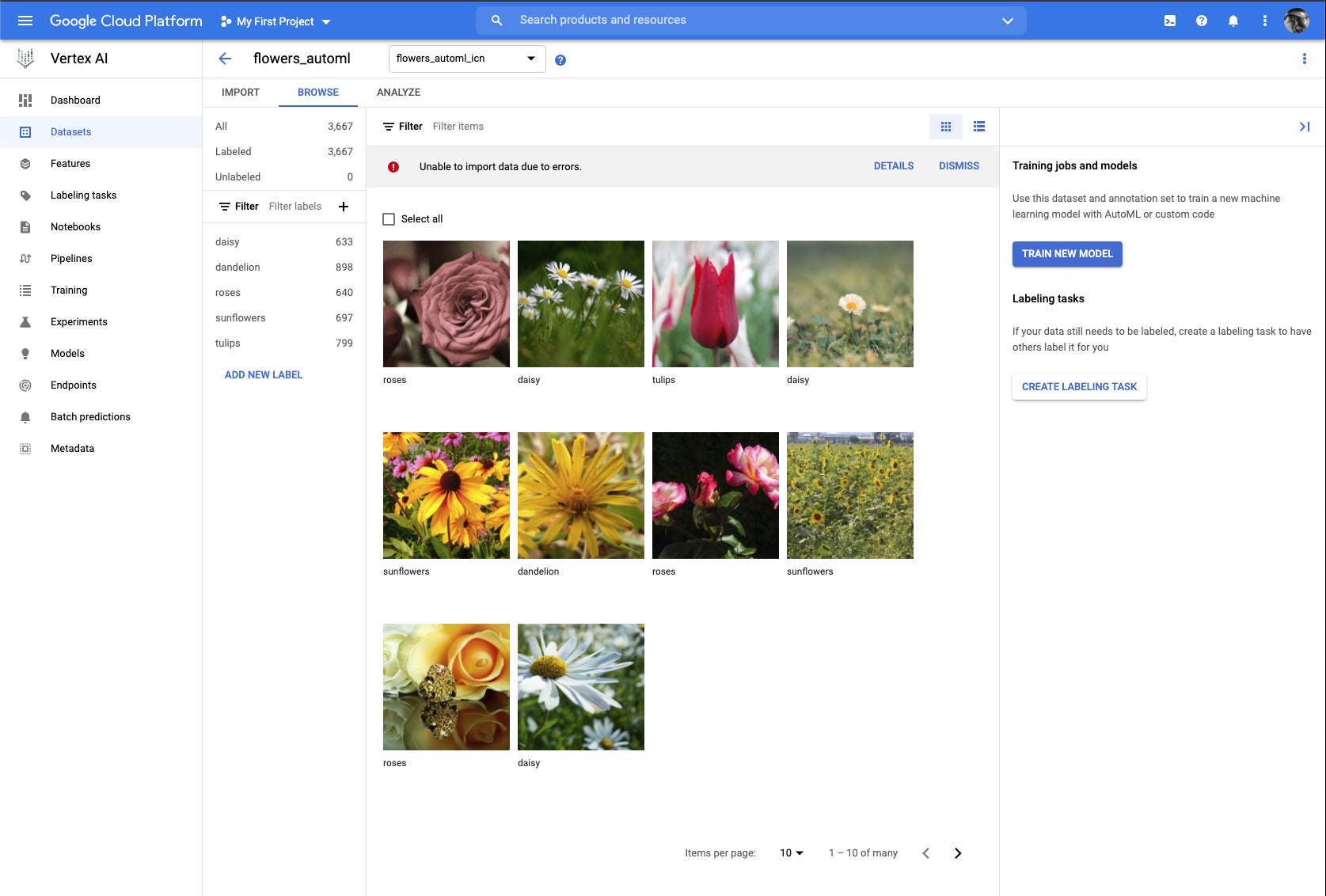
I ran the tutorial for AutoML Image using a dataset of flowers provided by Google. The training completed in about half an hour with a budget of eight node-hours. The node deployment for training was automatic. Between the training and a day of model deployment on one node (a mistake: I should have cleaned up the deployment after my testing but forgot), this exercise cost $90.
 IDG
IDG
Google supplied this labeled dataset of 3,667 flower images for the AutoML Image tutorial. Note the mislabeled daisy (tagged as a sunflower) at the left of the middle row.
 IDG
IDG
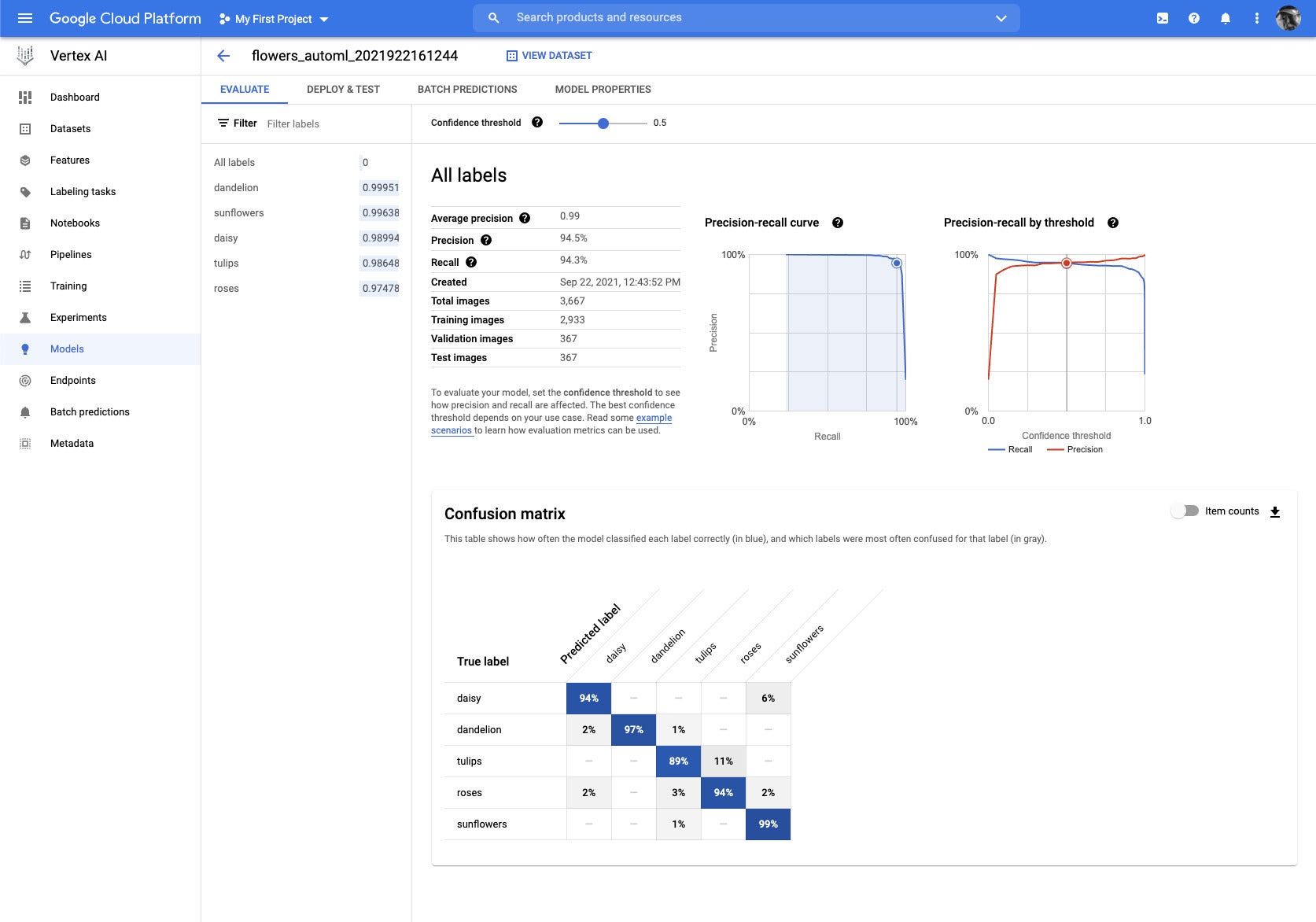
The flower classification model is pretty good judging by the precision and recall, but the confusion matrix hints at a few problems. It’s natural to sometimes confuse roses and tulips if the colors are similar and the shapes aren’t clear. Misclassifying daisies as sunflowers isn’t natural — but we saw a mislabeled daisy in the training set.
 IDG
IDG
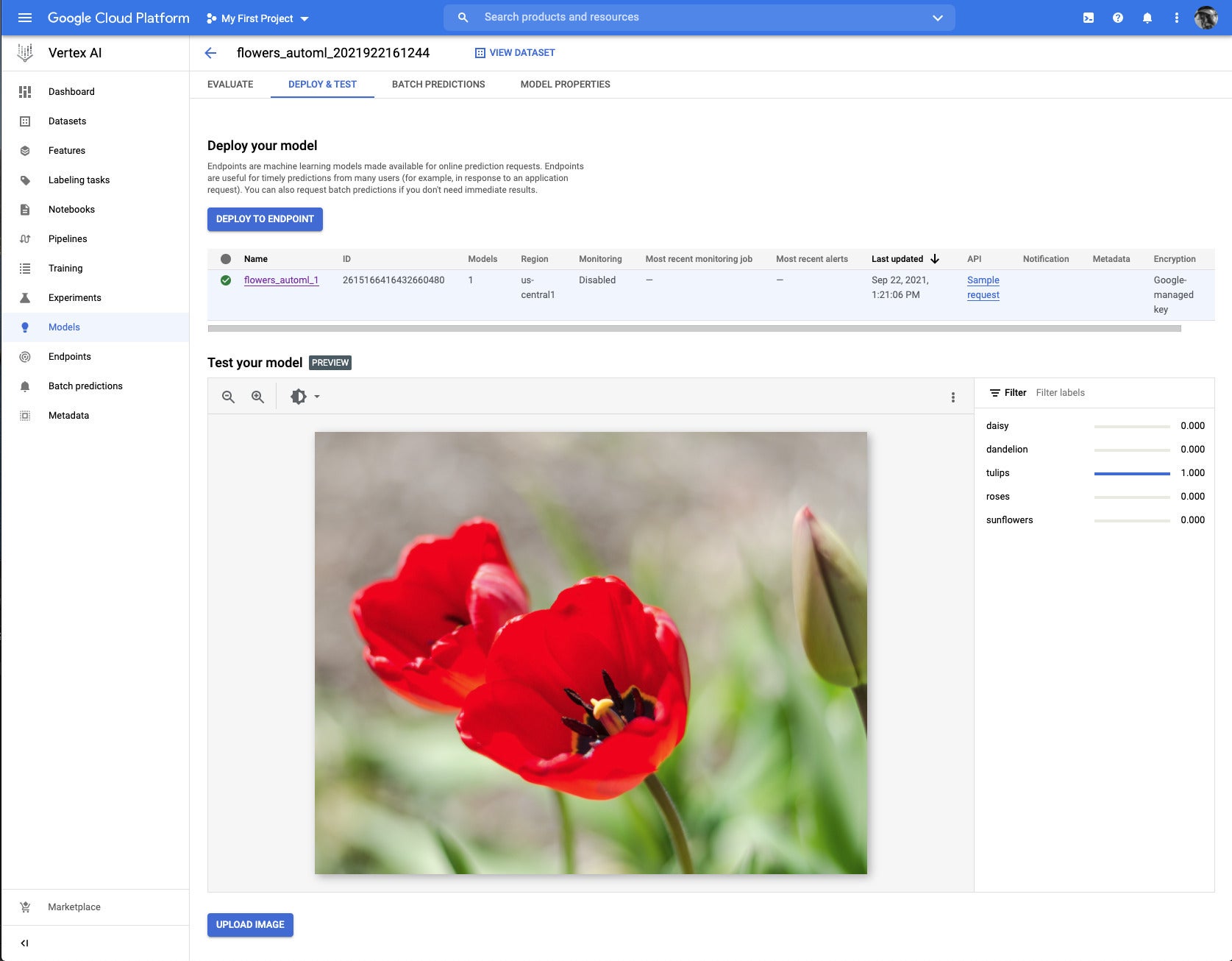
I tested the trained a model against a few of my own photographs, reduced in quality and size to fit the Vertex AI size limits. This image of tulips was identified correctly.
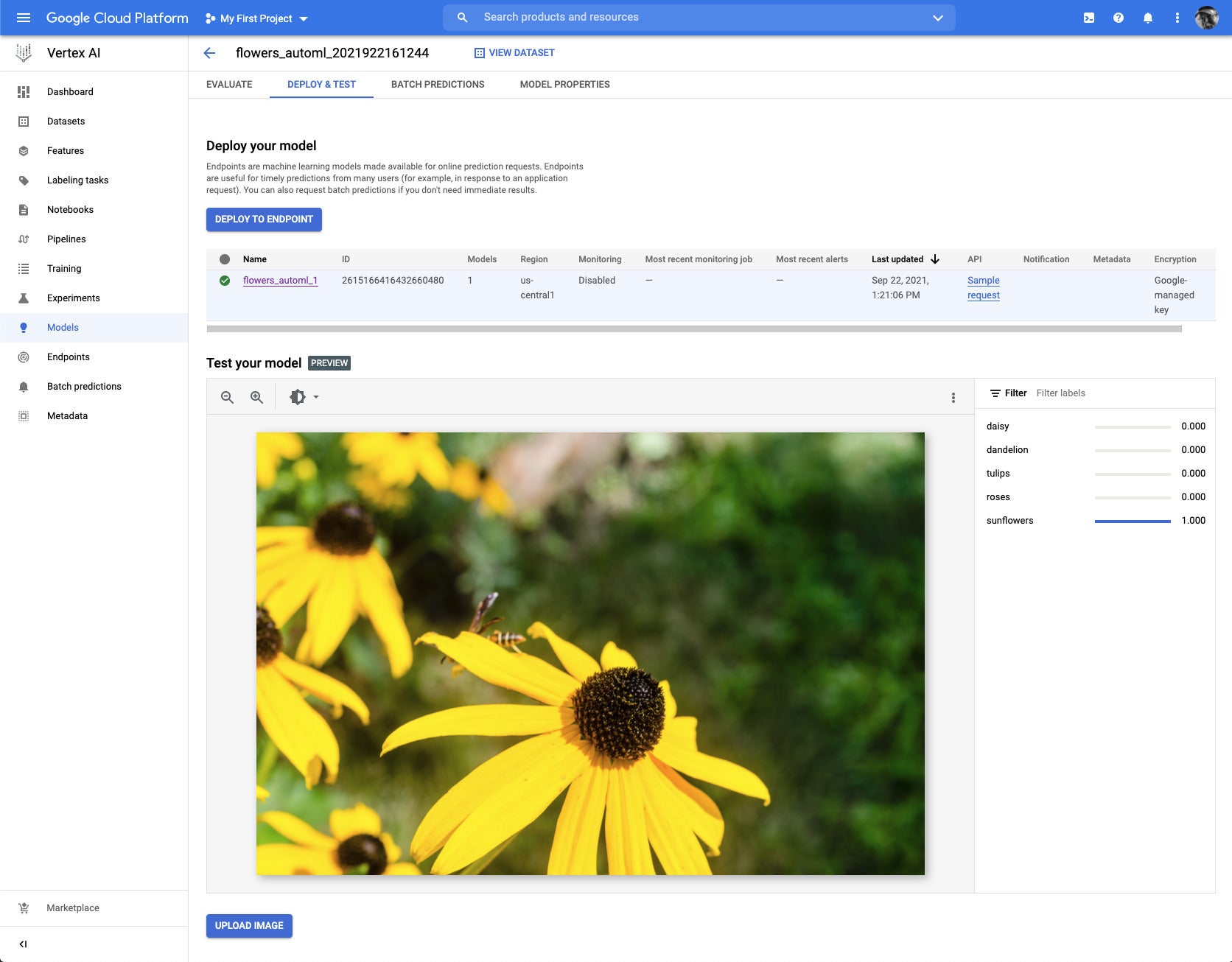 IDG
IDG
This image of a daisy (and a bee) was misidentified as a sunflower with 100% certainty. We saw the misidentified training image that likely caused this problem in a previous figure. “Garbage in, garbage out” applies to data science as much as it does to conventional computer programs.
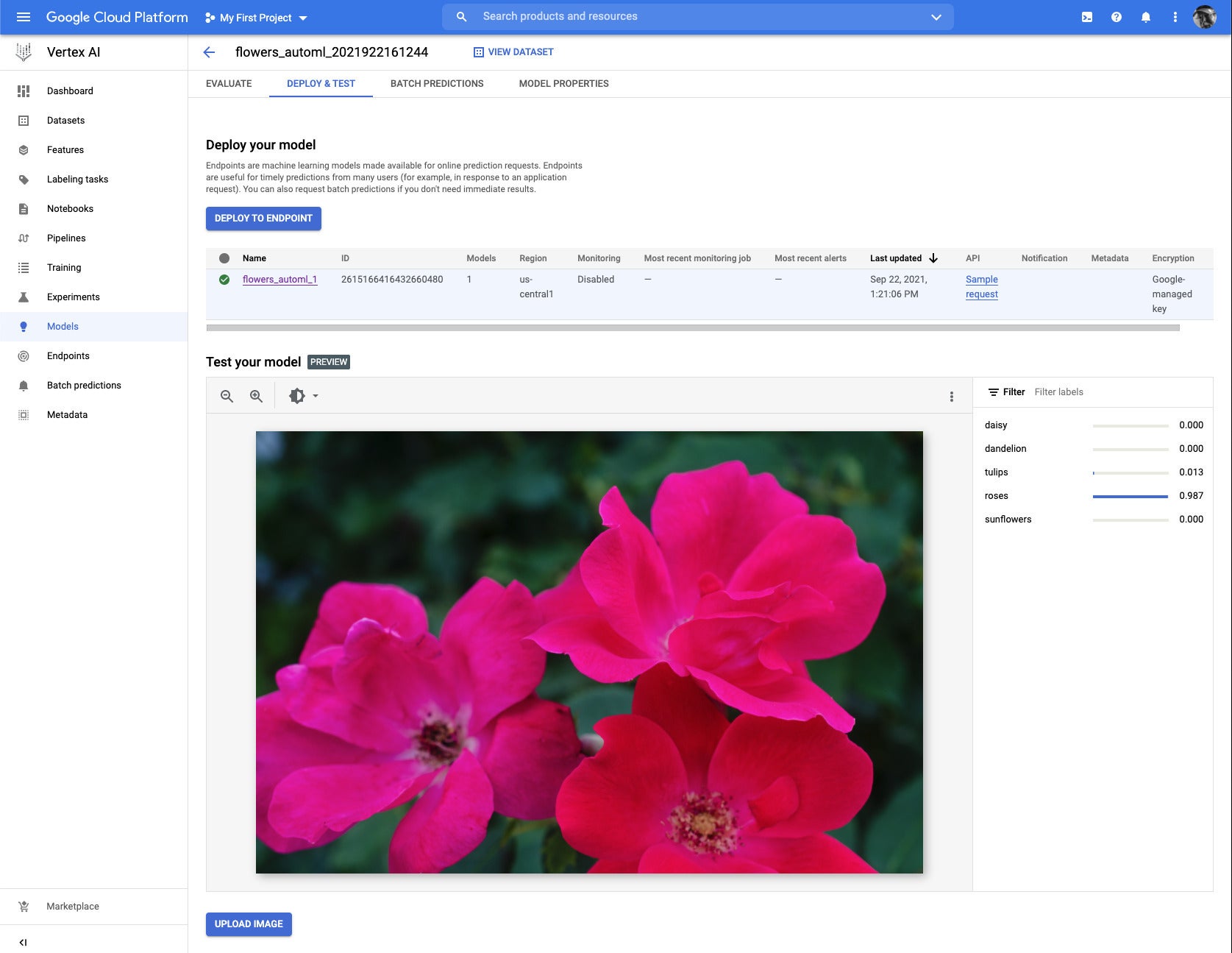 IDG
IDG
This photograph of roses was correctly identified at 98.7% certainty. The small probability of the image being of tulips is understandable.
As we’ve seen, a few badly labeled training images can cause a model to give wrong answers, even though the model exhibits high accuracy and precision. If this model were intended for real-world use, the labeled training set would need to be audited and corrected.
AutoML Tabular, which used to be called AutoML Tables, has a new (beta) forecasting feature, although no tutorial to test it.
I ran the tutorial for AutoML Tabular, which classifies banking customers and doesn’t include any time-based data. I gave the training a budget of one node-hour; it completed in two hours, reflecting time needed for other operations besides the actual training. The training cost of $21 was offset by an automatic credit.
By comparison, Azure Automated ML for tabular data currently includes forecasting, explanations, and automatic feature engineering, and may be a little ahead of Google AutoML Tabular at the moment. Azure also has forecasting tutorials both using the console and using Azure Notebooks. Both DataRobot and Driverless AI seem to be more advanced than Google AutoML Tabular for AutoML of tabular data. DataRobot also allows image columns in its tables.
 IDG
IDG
This is the initial screen for training a model on a tabular dataset. Note that the forecasting option is a preview and lacks a tutorial.
 IDG
IDG
You can monitor the progress and training performance of an AutoML training for tabular data as it runs. Here the training has completed.
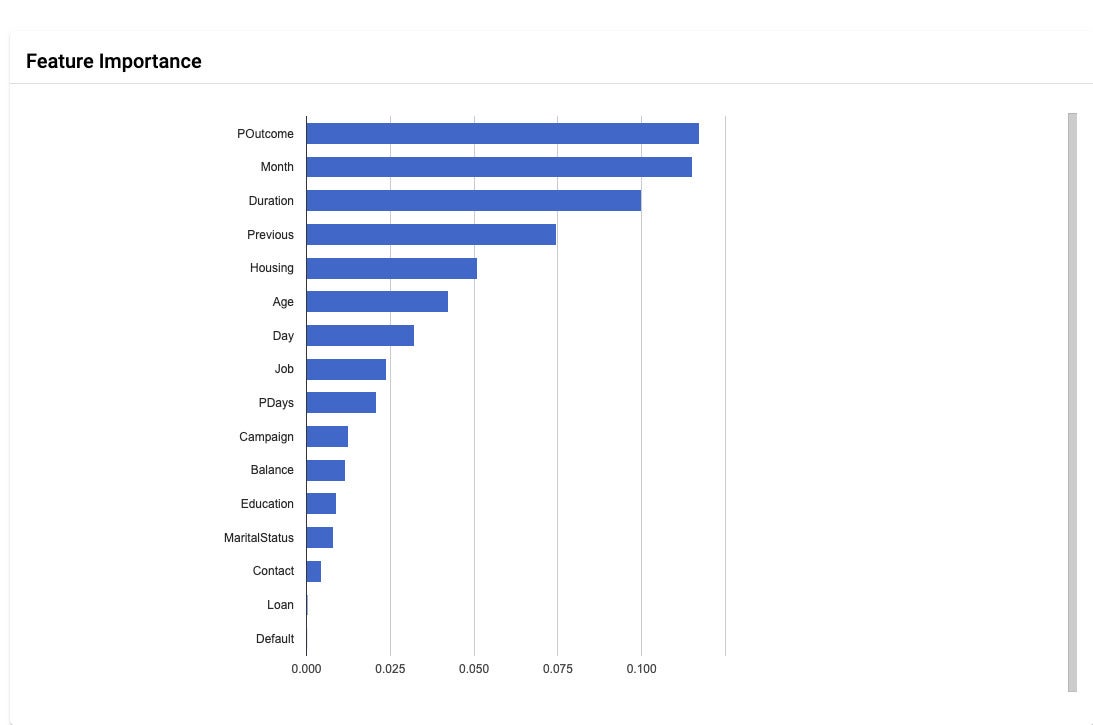 IDG
IDG
Vertex AI displays feature importance for AutoML models. Feature importance helps to explain the model.
Google AutoML Text supports four objectives: single-label and multi-label classification, entity extraction, and sentiment analysis. I didn’t run the text tutorial myself, but I read through the documentation and the notebooks.
The APIs demonstrated in the tutorial notebook are about as simple as they can be. For example, to create a dataset, the code is:
ds = aiplatform.TextDataset.create(
display_name=display_name,
gcs_source=src_uris,
import_schema_uri=aiplatform.schema.dataset.ioformat.text.single_label_classification,
sync=True,
)
The code to train a classification job is twofold, defining and then running the job:
# Define the training job
training_job_display_name = f"e2e-text-training-job-{TIMESTAMP}"
job = aiplatform.AutoMLTextTrainingJob(
display_name=training_job_display_name,
prediction_type="classification",
multi_label=False,
)
model_display_name = f"e2e-text-classification-model-{TIMESTAMP}"
# Run the training job
model = job.run(
dataset=text_dataset,
model_display_name=model_display_name,
training_fraction_split=0.7,
validation_fraction_split=0.2,
test_fraction_split=0.1,
sync=True,
)
The AutoML Video objectives can be action recognition, classification, or object tracking. The tutorial does classification. The trained model can be AutoML, AutoML Edge (to export for on-device use), or custom training. The prediction output for a video classification model is labels for the videos, labels for each shot, and labels for each one-second interval. Labels with a confidence below the threshold you set are omitted.
Importing models
You can import existing models that you’ve trained outside of Vertex AI, or that you’ve trained using Vertex AI and exported. You can then deploy the model and get predictions from it. You must store your model artifacts in a Cloud Storage bucket.
You have to associate the imported model with a container. You can use pre-built containers provided by Vertex AI, or use your own custom containers that you build and push to Container Registry or Artifact Registry.
Getting predictions
As we saw when we tested AutoML Image, you can deploy and test models from the Console. You can also deploy and test models using the Vertex AI API. You can optionally log predictions. If you want to use a custom-trained model or an AutoML Tabular model to serve online predictions, you must specify a machine type when you deploy the Model resource as a DeployedModel to an Endpoint. For other types of AutoML models, such as the AutoML Image model we tested, Vertex AI configures the machine types automatically.
Using explainable AI
We saw a feature importance plot for AutoML Tabular models earlier, but that isn’t the only explainable AI functionality offered by Vertex AI.
 IDG
IDG
Feature attribution overlays from a Google image classification model.
Vertex AI also supports Vertex Explainable AI for AutoML Tabular models (classification and regression models only), custom-trained models based on tabular data, and custom-trained models based on image data.
In addition to the overall feature importance plot for the model, AutoML tabular models can also return local feature importance for both online and batch predictions. Models based on image data can display feature attribution overlays as shown in the images below. (See “Explainable AI explained.”)
Tracking model quality
The distribution of the feature data you use to train a model may not always match the distribution of the feature data used for predictions. That’s called training-serving skew. In addition, the feature data distribution in production may change significantly over time, which is called prediction drift. Vertex Model Monitoring detects both feature skew and drift for categorical and numerical features.
Orchestrating ML workflow
Vertex Pipelines (preview) might well be the most important part of Vertex AI, given that it implements MLOps. While the value of MLOps may not be obvious if you’re just starting out in data science, it makes a huge difference in velocity, agility, and productivity for experienced data science practitioners. It’s all about getting models deployed, and making the feature engineering reproducible.
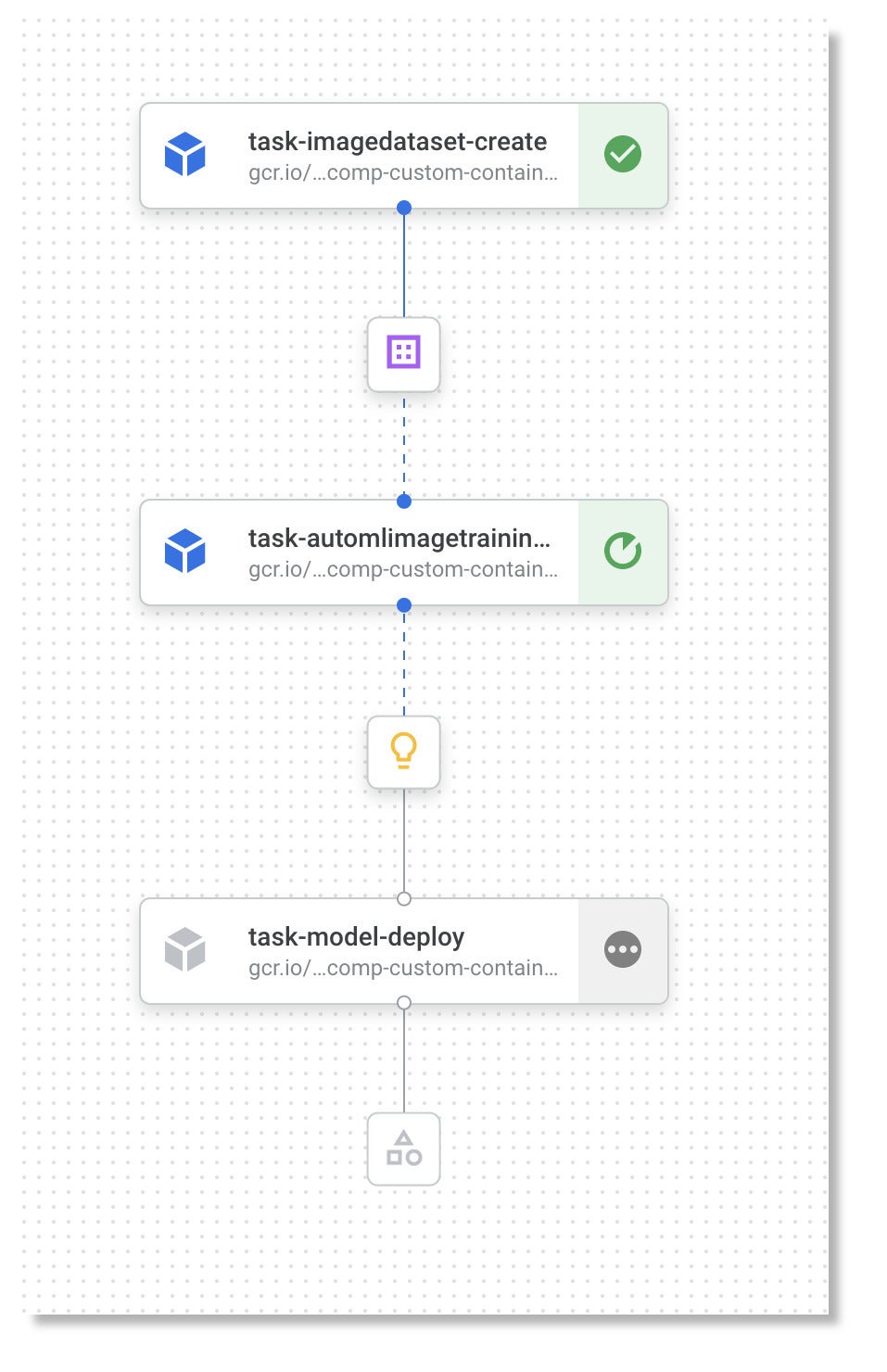 IDG
IDG
This image is a partially expanded graph for a Vertex Pipeline that classifies flowers using the same dataset and model as we used earlier.
Combining Vertex Pipelines with Vertex Model Monitoring closes the feedback loop to maintain model quality over time as the data skews and drifts. By storing the artifacts of your ML workflow in Vertex ML Metadata, you can analyze the lineage of your workflow’s artifacts. Vertex Pipelines supports two kinds of pipelines, TensorFlow Extended (TFX) and Kubeflow Pipelines (KFP). KFP can include Google Cloud pipeline components for Vertex operations such as AutoML.
Vertex Pipelines are competitive with Amazon SageMaker Pipelines and Azure Machine Learning Pipelines. Like Amazon SageMaker Pipelines, you create Google Vertex Pipelines from code, but you can reuse and manage them from the resulting graphs.